PyTorch (v1.1.0) implementation of ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation, ported from the lua-torch implementation ENet-training created by the authors.
This implementation has been tested on the CamVid and Cityscapes datasets. Currently, a pre-trained version of the model trained in CamVid and Cityscapes is available here.
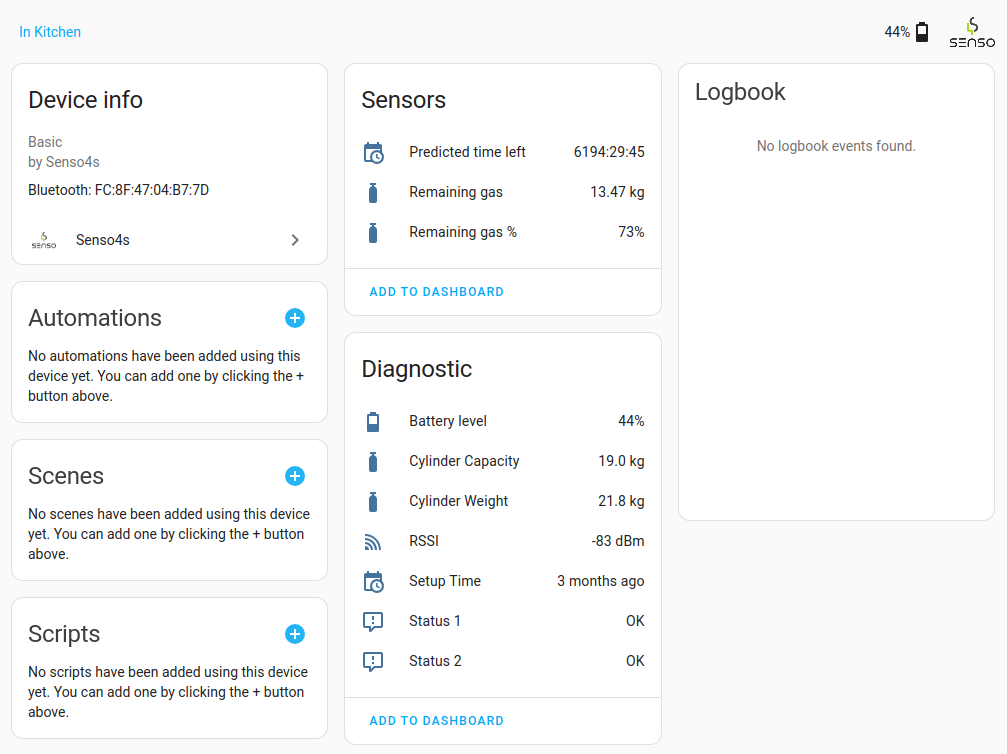
| Dataset | Classes 1 | Input resolution | Batch size | Epochs | Mean IoU (%) | GPU memory (GiB) | Training time (hours)2 |
|---|---|---|---|---|---|---|---|
| CamVid | 11 | 480×360 | 10 | 300 | 52.13 | 4.2 | 1 |
| Cityscapes | 19 | 1024×512 | 4 | 300 | 59.54 | 5.4 | 20 |
1 When referring to the number of classes, the void/unlabeled class is always excluded.
2 These are just for reference. Implementation, datasets, and hardware changes can lead to very different results. Reference hardware: Nvidia GTX 1070 and an AMD Ryzen 5 3600 3.6GHz. You can also train for 100 epochs or so and get similar mean IoU (± 2%).
3 Test set.
4 Validation set.
- Python 3 and pip
- Set up a virtual environment (optional, but recommended)
- Install dependencies using pip:
pip install -r requirements.txt
- Build the image:
docker build -t enet . - Run:
docker run -it --gpus all --ipc host enet
Run main.py, the main script file used for training and/or testing the model. The following options are supported:
python main.py [-h] [--mode {train,test,full}] [--resume]
[--batch-size BATCH_SIZE] [--epochs EPOCHS]
[--learning-rate LEARNING_RATE] [--lr-decay LR_DECAY]
[--lr-decay-epochs LR_DECAY_EPOCHS]
[--weight-decay WEIGHT_DECAY] [--dataset {camvid,cityscapes}]
[--dataset-dir DATASET_DIR] [--height HEIGHT] [--width WIDTH]
[--weighing {enet,mfb,none}] [--with-unlabeled]
[--workers WORKERS] [--print-step] [--imshow-batch]
[--device DEVICE] [--name NAME] [--save-dir SAVE_DIR]
For help on the optional arguments run: python main.py -h
python main.py -m train --save-dir save/folder/ --name model_name --dataset name --dataset-dir path/root_directory/
python main.py -m train --resume True --save-dir save/folder/ --name model_name --dataset name --dataset-dir path/root_directory/
python main.py -m test --save-dir save/folder/ --name model_name --dataset name --dataset-dir path/root_directory/
data: Contains instructions on how to download the datasets and the code that handles data loading.metric: Evaluation-related metrics.models: ENet model definition.save: By default,main.pywill save models in this folder. The pre-trained models can also be found here.
args.py: Contains all command-line options.main.py: Main script file used for training and/or testing the model.test.py: Defines theTestclass which is responsible for testing the model.train.py: Defines theTrainclass which is responsible for training the model.transforms.py: Defines image transformations to convert an RGB image encoding classes to atorch.LongTensorand vice versa.

https://github.com/davidtvs/PyTorch-ENet